Running large language models (LLMs) isn’t just expensive; it’s energy-hungry. While training gets most of the attention, it’s inference that dominates energy use. In contrast to training, which happens once or at intervals, inference runs continuously through every query, every user, every day. Recent estimates suggest that inference alone can account for up to 90% of a model’s total life cycle energy consumption, making it the true workhorse and energy sink of the LLM era.
To tackle this, most researchers focus on low-level optimizations such as KV caching and improved attention layers. With CacheSaver we propose something refreshingly simple: a client-side, plug-and-play caching layer that cuts LLM inference cost while harnessing the power of seeding to make LLM experiments fully reproducible without compromising the model’s statistical integrity.
A Universal Client-Side Optimization
CacheSaver is the first client-side framework to make high-level inference optimization practical. Instead of tinkering with model internals or server code, it adds a non-intrusive optimization layer that introduces intelligent reuse directly at the client side.
What makes this especially powerful is its universality. CacheSaver works with any model, whether it’s an open-source system running locally or a closed-source API like GPT-4 or Claude. It also complements, rather than replaces, existing low-level engines such as vLLM, SGLang, or paged-attention optimizations, achieving this with virtually no additional memory overhead.
Plug-and-Play Your Way to Cheaper Inference
 Fig. 1: One line of code turns any LLM client into a CacheSaver-powered, optimized inference pipeline.
Fig. 1: One line of code turns any LLM client into a CacheSaver-powered, optimized inference pipeline.
Perhaps the most striking feature of CacheSaver is how effortlessly it integrates. Enabling its optimization layer requires just one line of code, with no complex setup, no new APIs to learn, and no changes to your existing logic.
By simply wrapping your existing inference client with CacheSaver(), you unlock a full suite of optimizations. From that moment on, your experiments become faster, cheaper, and fully reproducible, all without altering how you interact with the LLM. It is a rare example where meaningful efficiency gains come without engineering friction: plug it in once and everything downstream benefits.
Bringing the Power of Seeding to LLM Inference
At the heart of CacheSaver lies a simple but transformative idea: bringing the concept of seeding to LLM inference. In traditional machine learning, random seeding ensures reproducibility of stochastic processes. Yet today’s LLM APIs offer no such control, and identical prompts can yield different outputs even under fixed sampling parameters.
CacheSaver bridges this gap through a namespace-aware, list-valued cache that preserves the natural randomness of generative models while enforcing deterministic ordering of responses. Within each namespace, samples remain independent and identically distributed, while across namespaces, identical prompts yield identical responses. This balance enables fully reproducible, asynchronous experimentation, a capability that is especially valuable for large-scale benchmarking, ablation studies, and multi-agent reasoning research.
 Fig. 2: Without CacheSaver (left), repeated LLM calls produce different results even with the same prompt. With CacheSaver (right), namespaces act like random seeds: maintaining randomness within runs while ensuring identical prompts yield the same results across experiments.
Fig. 2: Without CacheSaver (left), repeated LLM calls produce different results even with the same prompt. With CacheSaver (right), namespaces act like random seeds: maintaining randomness within runs while ensuring identical prompts yield the same results across experiments.
To see how CacheSaver makes inference reproducible, consider the example above. On the left, we use a standard OpenAI client. Each time the same prompt is sent, the model produces a new set of outputs even when all sampling parameters are identical. This randomness is expected, since LLM APIs today offer no way to control or fix a random seed, meaning that results can shift between runs or even within the same session.
On the right, the same experiment is repeated using CacheSaver. Here, the framework introduces the equivalent of a fixed seed through its namespace-aware caching mechanism. In Namespace 1 (NS1), the model generates its samples normally, each one remaining independent and identically distributed. In Namespace 2 (NS2), those same samples are retrieved directly from the cache in the exact order they were first produced. This preserves the statistical integrity of model randomness while guaranteeing deterministic reproducibility across experiments, a critical property for large-scale evaluation and benchmarking.
Reuse in Multi-Step Reasoning
Reasoning has become one of the defining capabilities of modern LLMs, but it also represents one of the most computationally expensive workloads. Frameworks such as ReAct, Tree of Thoughts, and Fleet of Agents rely on sequences of independent model calls that frequently revisit similar intermediate states or subproblems.
CacheSaver directly targets this setting by capturing and reusing overlapping computations that occur across reasoning steps. By recognizing when the same subproblem has already been solved, it avoids redundant inference while maintaining full statistical validity of the underlying model. This leads to substantial reductions in both computational cost and therefore carbon footprint, making complex reasoning workloads more both affordable and sustainable.
 Fig. 3: CacheSaver identifies and reuses overlapping computations in multi-step reasoning.
Fig. 3: CacheSaver identifies and reuses overlapping computations in multi-step reasoning.
To see how CacheSaver enables reuse in practice, consider the example below. Imagine an LLM-based reasoning agent handling two questions: “Who is older, President Trump or President Biden?” and “Is President Trump fit to hold office?” At first glance, these look like completely independent reasoning tasks.
As the agent works through each question step by step, it begins to gather relevant information such as Biden’s age for the first question and factors like age, citizenship, and residency for the second. Eventually, both reasoning paths converge on a shared intermediate step: looking up Trump’s age. With CacheSaver, once this information has been retrieved in one process, it can be reused in the other, eliminating redundant computation while maintaining consistent and statistically valid behavior across both reasoning chains.
CacheSaver in Action
To illustrate CacheSaver’s impact in real-world use cases let’s look at three common machine learning workflows: Hyperparameter tuning (A1), Ablation analyses (A2), and Benchmarking reasoning strategies (A3). Each of these involves running the same experiment many times with only small variations. A process that can quickly become expensive and time-consuming.
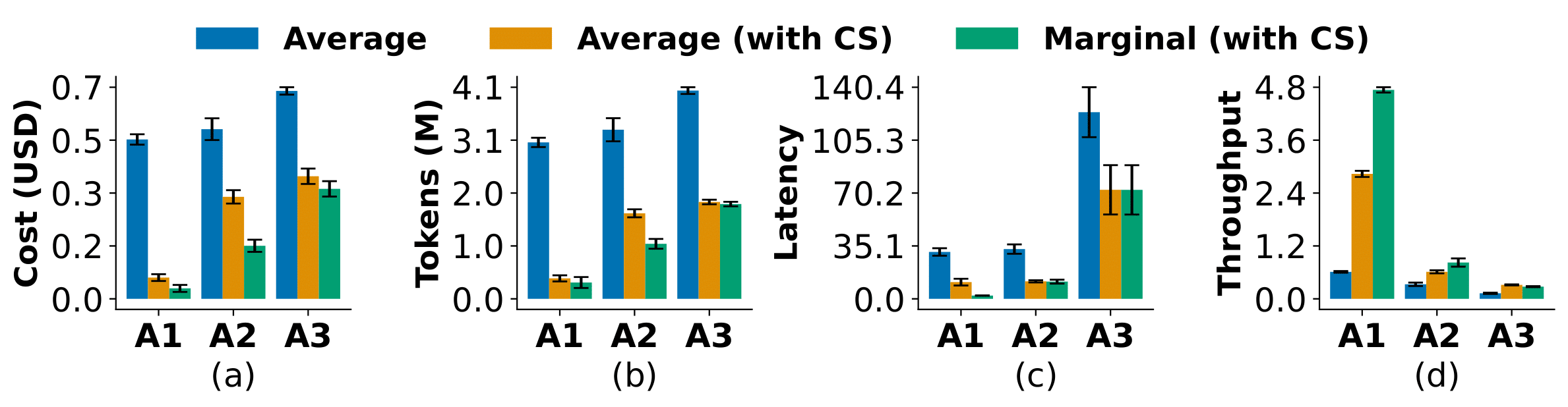 Fig. 4: Utilizing CacheSaver in A1: Hyperparameter tuning, A2: Ablation analysis and A3: Benchmarking.
Fig. 4: Utilizing CacheSaver in A1: Hyperparameter tuning, A2: Ablation analysis and A3: Benchmarking.
In the first experiment, CacheSaver was used during hyperparameter tuning of a reasoning framework (e.g. its width, depth, max number of steps, etc.). The impact was immediate: experiments ran six times cheaper and faster, with seven times higher throughput. Once caching was fully enabled, adding a new configuration came at almost no additional cost, since previously computed samples were automatically reused. When applied to ablation studies and benchmarking, CacheSaver continued to deliver strong gains: 2.5× cheaper for ablations and about 2× cheaper for benchmarking. These savings come from recognizing and reusing shared prompts and intermediate steps that appear across different reasoning algorithms.
Importantly, CacheSaver doesn’t just make experiments cheaper; it also makes them fairer and more comparable. By reusing the same underlying samples across runs, it ensures that every method is tested on identical generations rather than on different random draws. This shared randomness makes performance differences more meaningful and the comparisons far more reliable.
The takeaway is simple: whether you’re tweaking parameters, analyzing variations, or benchmarking entire frameworks, CacheSaver slashes cost and latency while improving experimental consistency. It turns repetitive experimentation into a faster, fairer, and more reproducible process.
🧩 Key Takeaways
⚙️ Client-side innovation: CacheSaver is the first client-side framework for high-level LLM optimization. It introduces intelligent caching and reuse without requiring access to model internals or server code.
🔌 Plug-and-play integration: One line of code enables automatic caching, batching, and reproducible seeding across any local or API-based model.
🎯 Reproducibility through seeding: CacheSaver brings deterministic behavior to LLM inference while preserving randomness, making experiments fully reproducible and statistically sound.
🔁 Efficiency in multi-step reasoning: By recognizing and reusing overlapping computations, it cuts redundant inference in reasoning-heavy workloads.
💸 Real-world savings: Across hyperparameter tuning, ablations, and benchmarking, CacheSaver reduces cost and latency by up to 6×, with nearly no additional memory overhead.
🌍 Better science, greener compute: Beyond cost savings, CacheSaver helps make large-scale LLM research more sustainable, consistent, and transparent.
🌱 Looking Ahead
We hope CacheSaver inspires broader exploration into making LLM research and deployment more sustainable, reproducible, and scalable. As models grow larger and reasoning pipelines become more complex, simple, modular tools like CacheSaver will play a key role in keeping progress both affordable and accountable.
Read further
All our code is available at this https URL.
Official BibTeX to be announced with EMNLP 2025.
@inproceedings{}