Large Language Models (LLMs) have unlocked new possibilities in building powerful autonomous agents. These agents are more than just chatbots. They’re tackling reasoning-heavy tasks like solving math problems, playing complex games, navigating websites, and even using external tools. But as promising as these AI systems are, making them both smart and efficient remains a major challenge.
 Fig. 1: A fleet of agents navigating the search space, looking for a solution
Fig. 1: A fleet of agents navigating the search space, looking for a solution
(image generated using GPT-4.o)
To tackle more complex problems, researchers have turned to multi-query methods that use iterative steps or tree-based searches to boost performance. But these gains often come with steep computational costs. That’s where Fleet of Agents (FoA) comes in: a new framework that strikes the ideal balance between capability and efficiency.
Key Highlights of This Work
- 🎯 A new framework, FoA, that improves how LLM-based agents reason, especially in complex or dynamic settings.
- 🧬 The first use of genetic-style particle filtering for navigating reasoning spaces in AI agents.
- 🧩 A plug-and-play runtime that works with existing AI agents, with no need to retrain or modify them.
- 📊 Comprehensive experiments across four challenging benchmarks and four LLMs, showing around 5% better results at only 35% of the cost compared to top-performing methods.
Survival of the Fittest: The Fleet of Agents Strategy
So, how exactly does Fleet of Agents (FoA) work? At its heart, FoA is a method for coordinating a team of AI agents, each independently exploring a problem space. Unlike traditional approaches, FoA applies a twist inspired by evolutionary biology. It selectively keeps and replicates the most promising agents based on how well they are doing.
A Fleet That Adapts and Evolves
Imagine starting with a fleet of agents—tiny reasoners—all tackling the same problem from different angles. Each agent enters a mutation phase and takes a few steps forward on its own, making decisions and moving through the problem space. Then comes the selection phase where the system employs a dynamic branching approach to focus its approach.
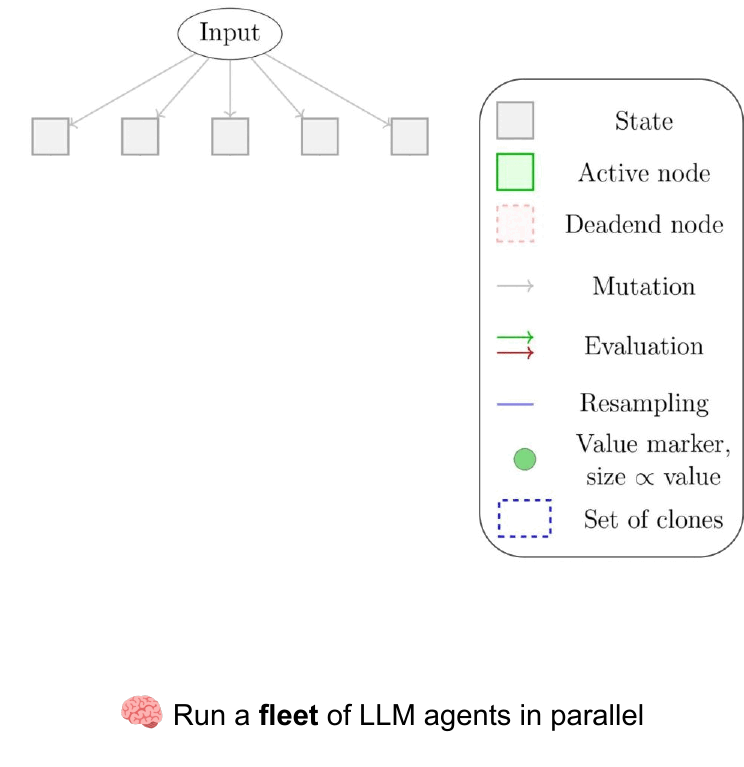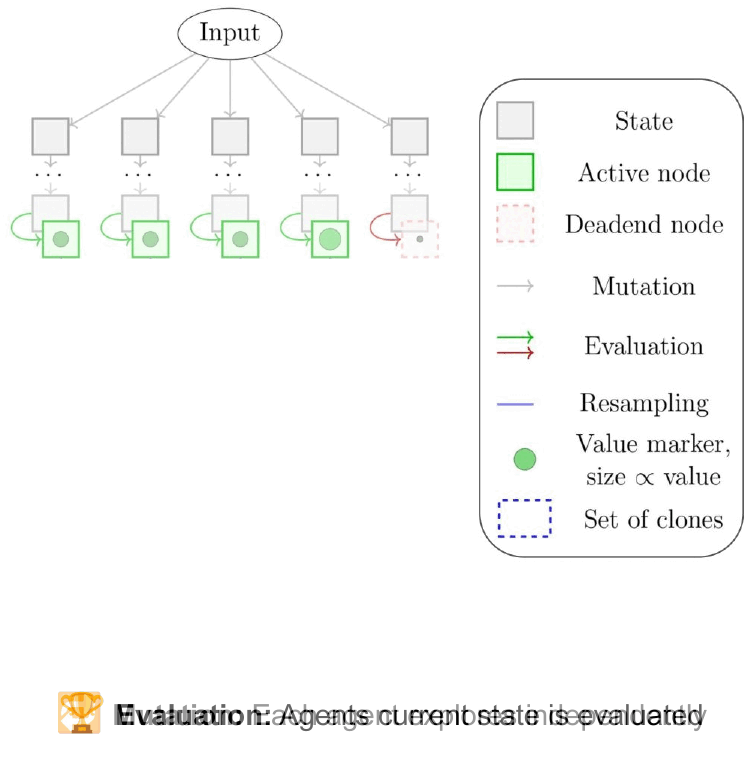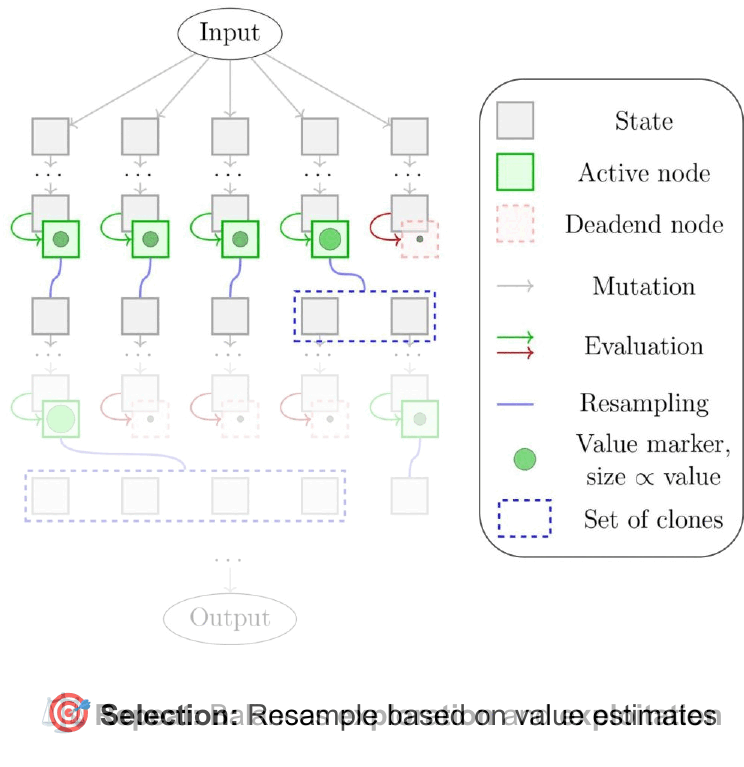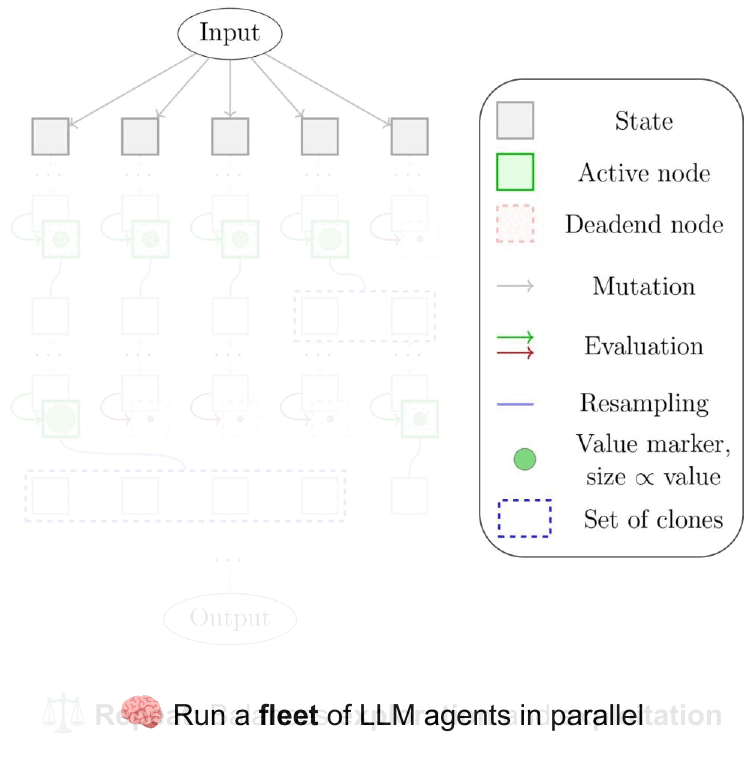 Fig. 2: Fleet of 5 Agents exploring and being resampled as they navigate the search space.
Fig. 2: Fleet of 5 Agents exploring and being resampled as they navigate the search space.
Mutation Phase: Independent Exploration
In the mutation phase, each agent explores by interacting with its environment. For example, in a game, it might take a series of moves. In a reasoning task, it might generate a series of thoughts or actions. Key behaviors include:
- Enforced Mutation: Every agent must move forward. It is not allowed to stand still or loop indefinitely.
- Sudden Death: If an agent ends up in a clearly invalid state, such as making an illegal move or writing a malformed response, it gets eliminated. To maintain the fleet size, a surviving agent is cloned to take its place. This avoids wasting resources on broken paths.
This phase is all about discovering diverse parts of the problem space.
Selection Phase: Keep the Strong, Rethink the Weak
After every round of exploration, FoA checks how well the agents are doing. Using their value scores, it selectively duplicates the best-performing agents—those in high-value states. This importance sampling ensures that stronger agents get more chances to continue, while weaker ones are filtered out.
The weighting mechanism can be tuned. The system can be tuned to favor top performers more aggressively or maintain diversity across the fleet. This lets FoA stay flexible and responsive to the complexity of the task.
Backtracking: A Safety Net for Smart Recovery
What happens if every agent heads in the wrong direction? FoA includes a built-in recovery mechanism called backtracking.
By keeping a memory of all the states explored so far, not just the current ones, FoA can rewind and revisit earlier, more promising positions. It uses a discount factor to prioritize more recent and relevant states, but it still considers older ones when needed.
This means the system does not just push forward blindly. It can reflect, regroup, and re-approach the problem from a better angle if necessary.
Putting FoA to the Test
To evaluate Fleet of Agents (FoA), we ran a wide range of experiments comparing it to leading reasoning frameworks. Our goal was to test how well FoA performs in solving complex problems that require logical thinking, planning, or multi-step decision-making, while also keeping costs low.
We benchmarked FoA on four diverse tasks using multiple large language models, including GPT-4, GPT-3.5, and two variants of LLaMA3. To ensure fairness, we reused prompts from previous works and reported both quality and efficiency (measured in dollars) across all evaluations.
🔗 For full code and details, visit our GitHub repository at this https URL.
Across the Board: Cost Meets Capability
Across all four benchmarks, FoA consistently led in both quality and efficiency. Whether solving logic puzzles, answering science questions, or navigating online stores, FoA proved that a well-coordinated fleet of reasoning agents can outperform more expensive, brute-force methods.
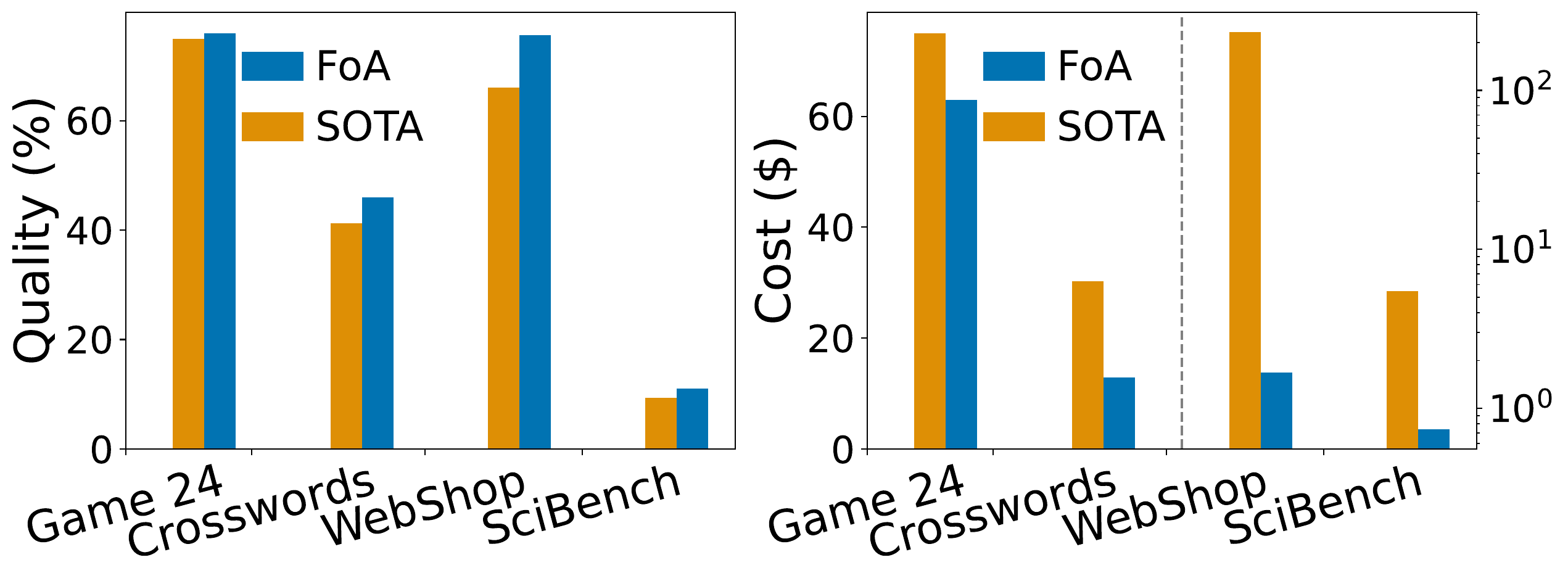 Fig. 3: Compare quality and cost of FoA against second best method on each benchmark.
Fig. 3: Compare quality and cost of FoA against second best method on each benchmark.
💡 FoA shows that smarter strategy beats raw scale. It delivers stronger results while saving compute, time, and cost.
How Well Does FoA Scale? A Closer Look
To see how Fleet of Agents (FoA) holds up in practice, we compared it against top methods, tested it under strict budgets, and evaluated how it performs with both small and large models.
📈 Better than the Best: Across all four benchmarks, FoA beat the strongest existing methods in both quality and cost. On average, it delivered 5 percent higher accuracy while using just 35 percent of the cost.
💰 Stronger Under Budget: In a fixed-budget setting on the Game of 24 task, FoA still came out on top. Even when other methods were given more attempts, FoA offered the best cost-quality trade-off across the board.
🧠 Small Models, Big Gains: We paired FoA with LLaMA3.2-11B and LLaMA3.2-90B. On their own, these models underperformed—but with FoA, performance jumped 5 to 6 times. In fact, FoA + 11B outperformed 90B on its own.
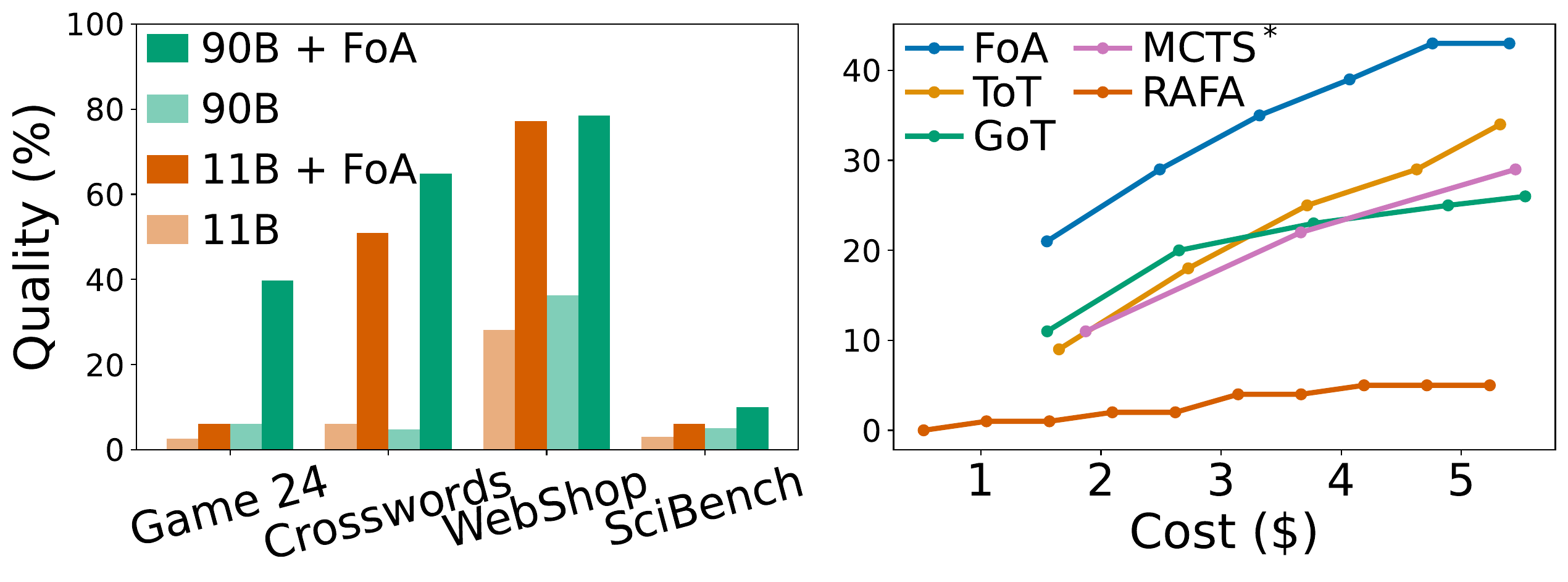 Fig. 4: Evaluating the trade-off between (Left) model size and quality with Llama3.2-11B and 90B as base models, and (Right) cost and quality of representative SOTA methods with GPT-3.5 on Game of 24.
Fig. 4: Evaluating the trade-off between (Left) model size and quality with Llama3.2-11B and 90B as base models, and (Right) cost and quality of representative SOTA methods with GPT-3.5 on Game of 24.
💡 Whether you are constrained by budget, compute, or model size, FoA helps you do more with less, without sacrificing performance.
🔍 Key Takeaways
✅ Better Model-Agnostic performance: FoA consistently outperforms top reasoning frameworks on every benchmark task, across multiple language models.
💸 Superior cost-quality trade-off: Even under tight budgets, FoA gets more done for less—offering up to 70 percent improvements at a fraction of the cost.
⚙️ Plug-and-play flexibility: Unlike prompt-heavy methods, FoA works as a runtime that integrates seamlessly with any prompting strategy or agent. No handcrafted prompts required.
📏 Predictable and tunable: FoA allows precise control over resources, making it ideal for deployment across varied environments or hardware constraints.
🔁 More stable: It produces more consistent results across runs, with less variability compared to other methods.
🚧 Limitations and Future Directions
Even though FoA performs strongly, there are exciting areas for future improvement:
🔄 Adaptive fleet sizes: Right now, the number of agents is fixed. We plan to explore smarter, dynamic allocation based on task difficulty.
🧠 Smarter resampling: Better value functions and resampling strategies could help FoA adapt its behavior—either becoming more exploratory or more focused when needed.
🧬 More complex fleets: Today, all agents are identical. What if we introduced hierarchy, coordination, or even nested fleets? FoA’s modular runtime design opens the door to rich organizational structures.
🌱 Looking Ahead
Our goal is to spark further research into combining evolutionary strategies and intelligent filtering to coordinate AI agents. FoA is just the beginning—a flexible, efficient way to scale reasoning that can evolve alongside future models and tools.
Read further
All our code is available at this https URL.
@inproceedings{
klein2025fleet,
title={Fleet of Agents: Coordinated Problem Solving with Large Language Models},
author={Lars Henning Klein and Nearchos Potamitis and Roland Aydin and Robert West and Caglar Gulcehre and Akhil Arora},
booktitle={Forty-second International Conference on Machine Learning},
year={2025},
url={https://openreview.net/forum?id=yNpYb376zf}
}